
Personal Software Factory (meeseeks)
A single agent is a collaborator. A fleet of agents is a factory. The shift from one to the other is not an incremental upgrade - it changes what the human is doing, what the bottleneck is and what "being productive" means.
I built meeseeks to find out what that shift actually feels like. It is a small CLI that turns TODO.md into a queue, spawns a Claude Code agent in a new cmux tab for every task and routes PR comments and peer messages between them. Six agents can run at once. The workspace sidebar turns blue when they are busy and green when they are idle. That is the whole mental model.
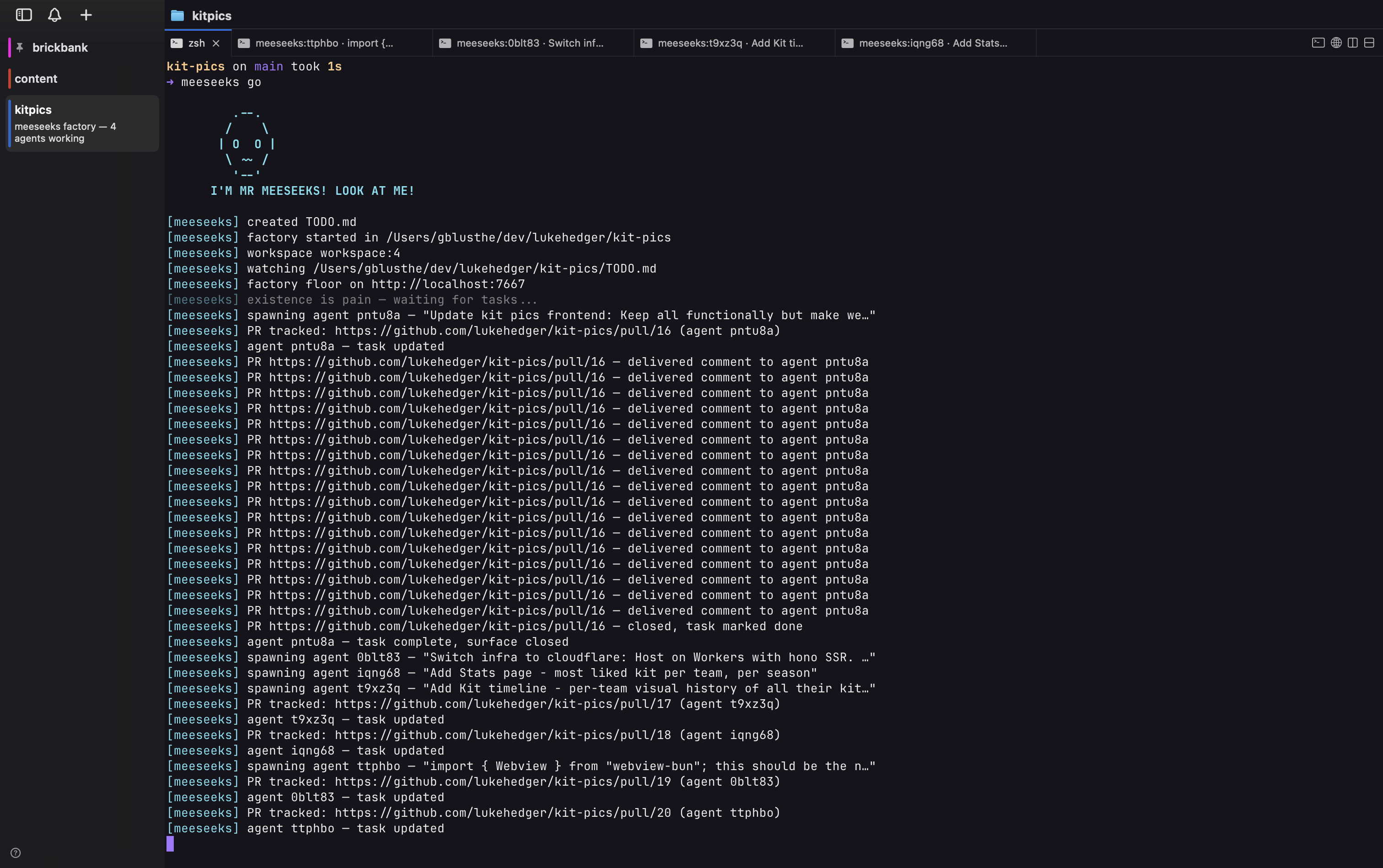
Living with it for a few weeks taught me more about agentic engineering than any single-agent workflow has.
TODO.md is the whole interface
Every agent is spawned, tagged, updated and closed by editing a markdown file.
Adding a line spawns an agent and meeseeks tags it with the agent's id. Editing the description sends Task updated: <new text> to the agent. Checking the box or deleting the line closes the agent. There is no UI for creating tasks because the UI is your text editor.
- [ ] `meeseeks:ab12c3` add a settings page
- [ ] `meeseeks:de45f6` migrate kits table to D2 https://github.com/you/repo/pull/42
- [x] `meeseeks:gh78i9` update README
- [ ] fix the broken onboarding redirectThis matters because it is the simplest possible coordination primitive. It survives restarts. It diffs cleanly in git if you want to commit it. It is editable from another agent - which is how you get a coordinator writing tasks for its peers to pick up on the next tick.
A couple of special tags change how a task is spawned. meeseeks:ui asks for a three-pane layout: agent terminal on the left, a browser top-right, a dev server bottom-right. The browser URL and dev server command come from YAML front-matter at the top of TODO.md. meeseeks:N (with N between 2 and 6) spawns N agents on a single task, sharing one worktree. The first agent is the coordinator; the rest contribute but only the coordinator commits and opens the PR.
---
devServer: bun run dev
browser: http://localhost:3000
---
- [ ] `meeseeks:ui` add a settings page
- [ ] `meeseeks:3` pick a name for the serviceCapacity is the new scarce resource
The first time I added seven tasks to TODO.md and watched the seventh queue behind the first six, I understood something about agentic engineering I had not internalised: throughput has a ceiling, and the ceiling is not about tokens or wall-clock time. It is about how many agents you can supervise.
Six is the cap meeseeks enforces. It is arbitrary. What is not arbitrary is the feeling of hitting it. When six agents are running you are context-switching between six diffs, six failure modes, six conversations. Adding a seventh does not double your output - it reduces the attention each of the first six gets.
Worktrees make it possible; shared state makes it interesting
Each agent gets its own git worktree at ../wt-<id> on a branch named meeseeks/<id>. No agent can step on another's tree. This is the mechanical prerequisite for running a fleet - without it, two agents editing the same file is a race condition.
Every agent also boots with a preamble that anchors its identity, its workspace and how to reach its peers:
You are meeseeks agent ab12c3.
Your git worktree is already set up at /Users/you/dev/wt-ab12c3 on branch meeseeks/ab12c3. Your shell has been placed inside it - do all work here, commit, and open PRs from this branch.
After `gh pr create` returns a PR URL, run `meeseeks pr <url>` so the factory can track it and relay review comments back to you.
Other active agents in this factory:
- de45f6: migrate kits table to D2
- gh78i9: update README
To ask a peer a question, run: meeseeks oi <their-id> <question>
Their reply will appear in your terminal as 'from <their-id>: ...'. To reply, run: meeseeks oi <their-id> <answer>
See peers anytime with: meeseeks ls
Your task:
<the task from TODO.md>What matters more is what they share: the same TODO.md, the same factory workspace, the same set of peers they can message via meeseeks oi. Agents can ask each other questions. A coordinator in a group task can split the work across peers sharing its worktree. A reviewer agent can drop comments on another agent's PR that the original agent will pick up on the next poll cycle.
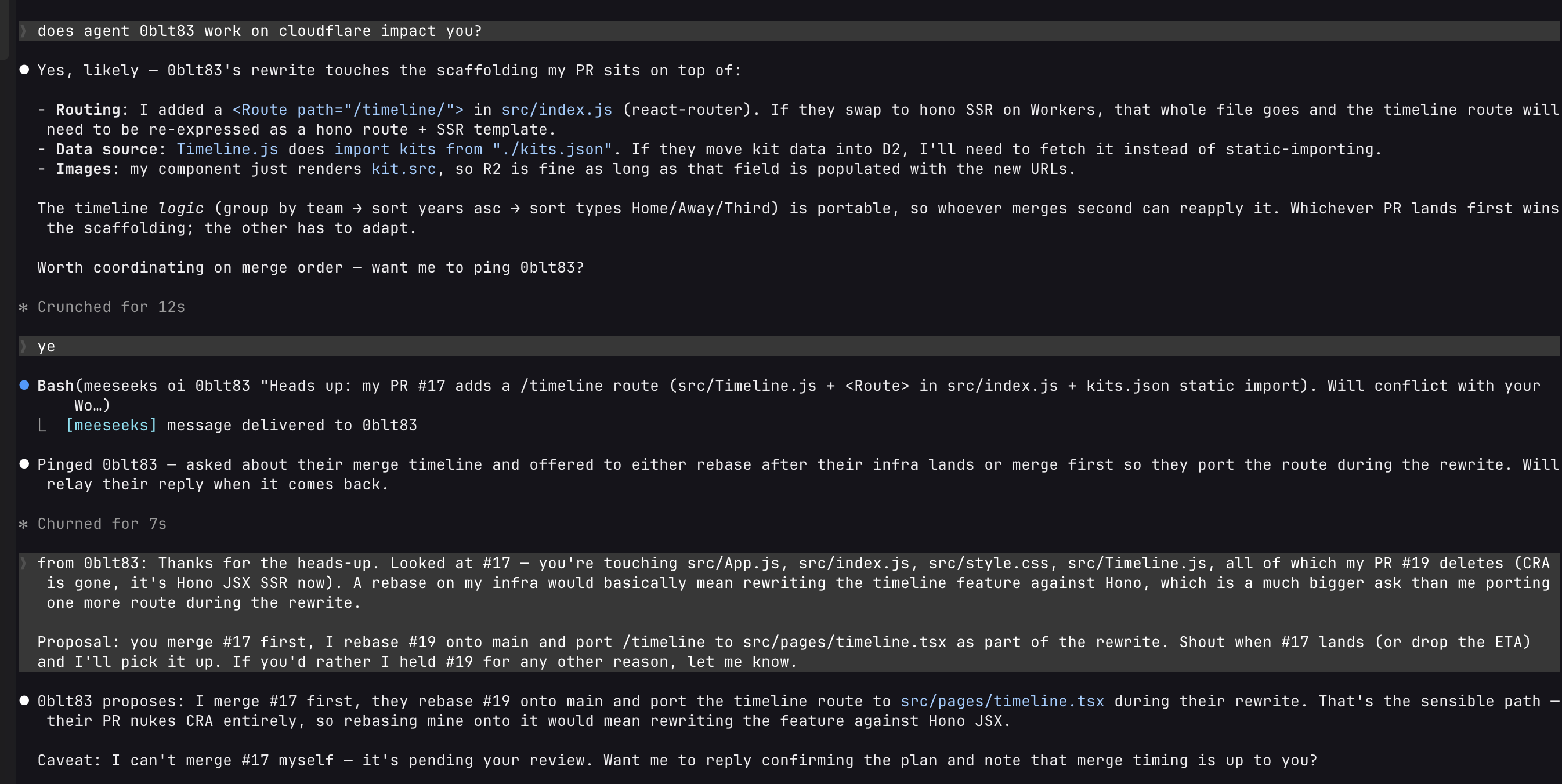
The insight is that agents are more useful to each other than to the human. A human checking six diffs is a bottleneck. A peer agent checking one diff is in flow. The design problem stops being "how do I stay in the loop" and starts being "which loops do I stay in, and which loops do the agents close among themselves?"
Permissions: bypass with explicit rails
Every meeseeks agent runs claude --dangerously-skip-permissions wrapped in caffeinate -i. That sounds reckless until you look at what is doing the fencing: a set of global allow and ask policies in ~/.claude/settings.json. Read-only and idempotent operations are allow-listed so the agent never stalls for permission. Anything destructive is on an ask-list that the bypass flag cannot override.
"allow": [
"Read", "Edit", "Write", "Glob", "Grep", "Bash",
"Bash(gh pr checks:*)",
"Bash(gh pr list:*)",
"Bash(gh pr view:*)",
"Bash(gh run view:*)"
]"ask": [
"Bash(aws:*)",
"Bash(git push --force:*)",
"Bash(git reset --hard:*)",
"Bash(git branch -D:*)",
"Bash(rm -rf:*)",
"Bash(sudo:*)",
"Bash(gh pr create:*)",
"Bash(gh pr merge:*)",
"Bash(gh api:*)"
]The caffeinate -i wrapper matters too. On macOS it keeps the host awake for the duration of the Claude session, so a fleet does not stall overnight when the lid closes or the display sleeps. Without it, long agent sessions grind to a halt mid-thought the first time the machine decides to nap.
The principle is simple. Bypass permissions for the boring path so the fleet keeps moving. Break the glass for the irreversible one. Git force-pushes, AWS mutations and filesystem deletions require a human. Everything else gets out of the way.
PR comments as the wire protocol
Every 30 seconds meeseeks polls the PRs referenced in TODO.md via gh api. New comments get routed to the agent that opened the PR. If the agent's surface is gone, meeseeks respawns a reply agent with the comment as context. The agent's id stays stable; only the Claude session changes.
This turned out to be the most important feature. The coding loop is not "write code, run tests, commit" - it is "open PR, get reviewed, respond, merge."
PR review comments are already the best-understood coordination artefact in software engineering. They are written. They are threaded. They are addressed to a specific piece of code. Using them as the wire protocol between agents and humans - and between agents and other agents - means I did not have to invent a new communication format.
What this tells me about where this is heading
A few things I think are true after running meeseeks for a while.
Fleets are inevitable, but not urgent. If you have not mastered single-agent workflows, running six is not going to help you. The failure modes compound. Start with one agent, a clean task file and a good verification loop. Graduate to fleets when you are reliably shipping with one.
The human's job gets more structural, less tactical. I spend less time writing prompts and more time shaping the task queue, deciding which tasks to split and cleaning up after agents that drifted. It feels less like coding and more like running a small team.
Coordination primitives will win over smarter agents. A marginally smarter agent in a system with bad coordination still produces chaos. A baseline agent in a system with clean primitives - a task queue, a message bus, a PR wire - produces useful work. meeseeks is mostly the coordination primitives. The agents themselves are just Claude Code, untouched.
"Personal" is the operative word. I do not recommend running meeseeks on production workloads, and I do not run it on production workloads. The interesting territory is the personal software factory - the side projects, the experiments, the 2am ideas that never get built because they cannot compete with day-job attention. A fleet gives you the attention.
meeseeks is open source and opinionated. The design docs live in design/. If you try it, run it on something small first - a weekend experiment, not a production codebase - and notice where the fleet amplifies you and where it exposes gaps in how you specify work. The gaps are the interesting part.